Although 3-dimensional arrays are not the most common object used among the R projects, which are dominated by data.frame-like objects. However, when we’re starting to work with deep learning, (e.g. using {keras}), we can run into such objects many times, especially in fields like time series forecasting or NLP.
The question I’d like to answer in this post is how to find ‘flat’ equivalent of the three-element index for the 3-dimensional arrays.
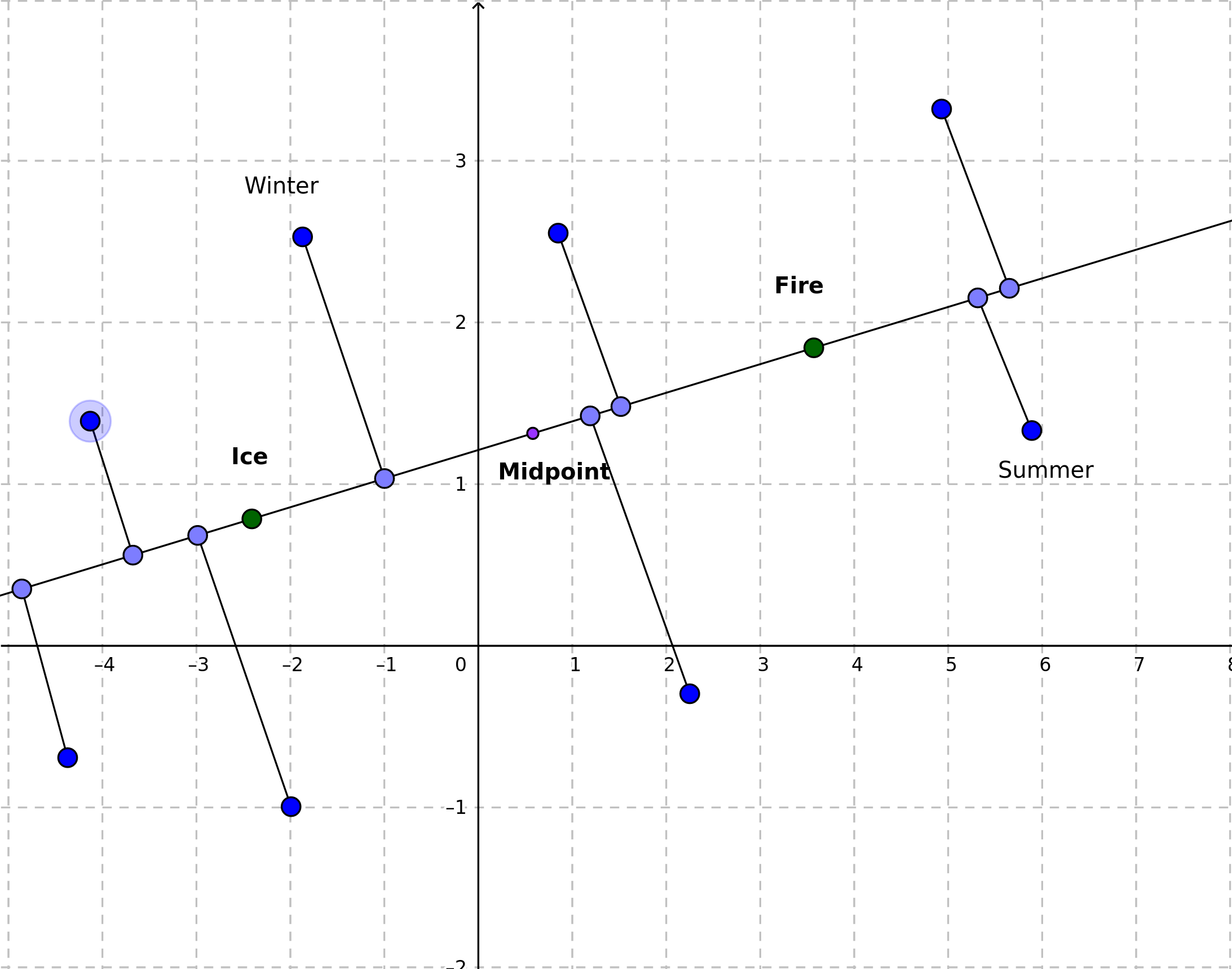
We all know old, good and hackneyed examples, that are typically used to intuitively explain, what the word embedding technique is. We almost always come across a chart presenting a simplified, 2-dimensional vector representation of the words queen and king, which are distant from each other similarly as the words woman and man.
Today, I’d like to go one step further and explore the meaning of the mutual position of two arbitrary selected vectors.
Conditional RNN is one of the possible solutions if we’d like to make use of static features in time series forecasting. For example, we want to build a model, which can handle multiple time series with many different characteristics. It can be a model for demand forecasting for multiple products or a unified model forecasting temperature in places from different climate zones.
We have at least a couple of options to do so.
In the previous year, I published a post, which as I hoped, was the first tutorial of the series describing how to effectively use PyTorch in Time Series Forecasting. Recently, a new exciting R package was submitted on CRAN. This great news was officially announced on the RStudio AI Blog. Yes, you mean right - the R port of PyTorch - called simply torch came into play. This encouraged me to reactivate my series, but in this time with both R and Pythonic versions.
Remake About two weeks ago, I published on my blog a comparision between two possible implementation of double-dispatch: S4-based and vctrs-based. It turned out, that in my trials vctrs performed better. However, two days later I’ve got a message from Lionel Henry via comment to my commit on GitHub. He suggested, that S4 got faster in the newest versions of R.
I decided to remake this experiment and check out, if my findings are still true.
path.chain package provides an intuitive and easy-to-use system of nested objects, which represents different levels of some directory’s structure in the file system. It allows us to created a nested structure, which returns a string from every its leaf.
Look at the path.chain Sometimes one picture can say more, than a thousand words, and this is exactly the case.
Motivation I’ve been working on the ML project, when we decided to keep strcture of the input data in the YAML config.
In most cases, when writing R scripts or even creating R packages, it is enough to use standard functions or S3 methods. However, there is one important field that forces us to consider double dispatch question: arithmetic operators.
Suppose we’d like to create a class, which fits the problem we’re currently working on. Let’s name such class beer.
eponge is a small package, which facilitates selective object removal. It was released on CRAN at 23th March 2020. Initially, the package was named sponge, but during first submission trial I found out, that currently there exists the SPONGE package, availbale on BioConductor. Because of that, I decided to rename my package, changing only one letter. The package was given a new name: eponge, which simply means sponge in French.
matricks package in 0.8.2 version has been released on CRAN! In this post I will present you, what are advantages of using matricks and how you can use it.
Creating matrices The main function the package started with is m. It’s a smart shortcut for creating matrices, especially usefull if you want to define a matrix by enumerating all the elements row-by-row. Typically, if you want to create a matrix in R, you can do it using base function called matrix.
When it comes to applying neural networks to Time Series processing (or other kind of sequential data), first words that we’ll probably think of are recurrent and convolutional layers. That’s absolutely right! In this post we’ll pass, step-by-step, through one of the simpliest examples of convolutional layer application i.e. training network to compute moving average. Such example may seem to not be practical, however its simplicity allows us to trace whole process and understand, how to control network’s behaviour, to model the way the network works.